Data consistency and performance in web applciation
Introduction
In this article we are going to look at various implementations of bank transfer in a web applciation API taking into consideration data consistency and performance.
Technologies and software I am using in examples below are: PostgreSQL, Java 17, JDBC, Spark Java, JMeter, Postman, IntelliJ
Approach 1 - plain SQLs
We start by creating a following piece of code to perform a bank transfer:
In terms of DB operations we can write it in following way:
- SELECT source account balance
- SELECT target account balance
- UPDATE source account balance
- UPDATE target account balance
We can test how will it behave when there are multiple users performing transfers concurrently. In my case I am going to place this code in a simple Jetty server and use JMeter to simulate the traffic.
Here is the JMeter load testing thread config (please note that same user on each iteration is unchecked):

with web server request config:

and payload:

As you can see we will perform 100 POST requests, each one exactly the same - sending 10 money from Tom's account to John's account, which means 1000 in total will be sent from Tom to John. Lets take a look at their initial balance:

Both at the beginning have 10 000 account balance, so at the end of experiment Tom should have 9 000 and John 11 000. Lets start the experiment and see the results:

It looks pretty bad. Tom has too much money (+380) and John not enough (-410). What is the reason? We can examplain it based on following example of two concurrent requests to transfer money:
| REQUEST 1 | REQUEST 2 |
| SELECT source account balance (10 000) | |
| SELECT target account balance (10 000) | |
| UPDATE source account balance (9 990) | |
| SELECT source account balance (9 990) | |
| SELECT target account balance (10 000) | |
| UPDATE target account balance (10 010) | |
| UPDATE source account balance (10 980) | |
| UPDATE targetaccount balance (10 010) |
Request 2 is selecting the target account balance value just before Request 1 is updating it. It means that Request 2 does not see the update and instead of updating target balance to 10 010 + 10 it is doing the same update as Request 1 - setting target balance to 10 000 + 10. Which effectively means we are loosing one update. What is even worse the source balance is updated by both transactions (-20) which means that we took 20 money from source account but effectively transfered only 10 to target account. Half of the money dissapeared.
Theres is another obvious drawback of this solution. There is no transaction being opened and commited/rollbacked in our code. It means that the whole bank transfer will not behave as atomic operation. It could lead to data inconsistency if there is any failure in the mid of the updates
.
How to improve it? Lets make bank transfer an atomic operation.
Approach 2 - read commited database transaction
Lets modify bank transfer code so that in runs in one database transaction:
Transaction will run in the default PostgreSQL isolation level - Read Commited. Now lets run exactly same test again - Tom and John both have 10 000 each and we perform 100 requests to move 10 money from Tom to John. Resulting account balances are following:

It doesn't look good. Tom still has to much money (+260) and John not enough (-200). We still have a serious issue with account balance inconsistency - Tom's balance has decreased by 740 while John's balance has increased by 800 which means that amount of 60 was 'magically' created. The reason is actually the same as it was described in the no-transaction approach. Why is that? The anomaly that was described in the previous section is called Lost Update. We are running on PostgreSQL with default isolation level Read Commited which does not resolve this anomaly. Did the change to read commited do any good at all? Yes, we are no longer vulnerable to inconsistencies resulting from exceptions or errors happening in the middle of account updates - in that case transaction will simply be rollbacked.
Lets try to increase transaction isolation level to get rid of the Lost Update anomaly.
Approach 3 - repeatable read transaction
Lets see change the isolation level by invoking following line of code before the bank transfer is performed:
Now we will run the experiment again. Results are following:

First thing we can see is that Tom and John still don't have expected balance (9000 and 11000). However the data is consistent. The same value was taken from Tom's account and added to John's balance. That is a much better result than previously. Why did it happen? We can take a look at application logs:

We see that not all requests have passed. In case of concurrent updates being performed by two transactions on the same account row one of them fails and is being rollbacked. Thanks to this database mechanism we achieve consistency and get rid of lost update phenomena. The price we pay are transactions that are rollbacked - not all requests are finished succesfully. The extremely important step is achieved though - data consistency.
Approach 4 - optimistic locking
We could achieve similar result when using optimistic locking approach. Repeatable Read and other isolation levels in PostgreSQL are using MVCC mechanism which is 'optimistic' since each transaction can store its own version (copy) of row without blocking each other by locking the same row. When two transactions are being commited and each one of them made changes to the same logical row then one of the will be rollbacked. Similar idea stands behind an optimistic locking approach where we usually add a version column to a row. Before performing the update we check if version was changed by other transaction in the meantime. If it was, then we rollback the transaction. The difference is that optimistic locking is handled on the application side while Repeatable Read is a database isolation level setting.
Lets take a look at the bank transfer implementation changes with optimistic locking. First thing is a new accounts table column - version.
Next thing we want to do is to increase the version when modyfing account row. There is also an additional condition - the update is performed only when the previously read row version is still the same (was not changed by other transaction):
and SQL params (for transfer from the account):
Last thing we need to do is handling situation when the update was not performed due to version collision. Example for source account:
When the exception is chached the transaction is obviously rollbacked:
Lets run the experiment transfering money (1000) from Tom to John and see the results:

The data is consistent - John has 790 more in the account and Tom has 790 less. We again see that not all the money was transfered. Lets take a look at application logs:

As you can see we've again faced Optimistic Locking exceptions - this time those exceptions are being thrown using application-level Optimistic Locking implementation.
The question is when to use Optimistic Locking and when repeatable read? The outcome looks very similar. The important thing to remember is that this outcome is similar since in PostgreSQL repeatable read implementation is not blocking due to MVCC mechanism. In other databases (like SQL Server) going with Repeatable Read could have a significant impact on the performance due to locks that are acquired when this isolation level is used. In that case going with optimistic locking could give us a better performance.


We will be simulating 100 users with 50 seconds ramp-up period and whole experiment will take 150 seconds. It means that number of users will gradually rise during the first 50 seconds and then during 100 seconds all 100 users will be active.


How to avoid concurrent update (or optimistic locking) errors? First thing to note is that we do not always need to do it. We might be fine with concurrent update errors if they are handled correctly and its acceptable for a client system. If we want to avoid it we could decide to do a pessimistic locking.
Approach 5 - pessimistic locking
Lets change the SELECT statement that we use to fetch an account data to a following one:
This is a SELECT FOR UPDATE statement which not only retrieves data but also applies a lock on selected rows to prevent updates and deletes. There is one more thing we need to do due to that. In the current code we always SELECT source account data first and target accound second. Since the SELECT statement results in a lock it could lead to a deadlock when the first transaction is performing a transfer from A to B and the concurrent one is doing a transfer from B to A. The solution is to acquire the lock always in the same order:
Lets start experiment and see what are the account balances at the end:

As you can see the data is consistent and all the requests were finished. Tom has 1000 less money and John has 1000 more in his account balance. Does it mean that pessimistic locking is always the best approach? No. We again do a trade - all requests are finished and data is consistent but there might be an impact on performance. Lets try to measure it.
Comparing performance
We are going to measure response times from two web endpoints:
- Already known - accout balance transfer endpoint.
- New one - an endpoint retrieving all the accounts with balances.
This way we can verify the performance taking into consideration an impact on data retrieval performed in the new endpoint. Lets take a brief look at the code on new endpoint:
We can see there is a simple SELECT statement used which retrieves all the accounts from the table.
Lets prepare the experiment that compares the performance (API response time). We are going to verify three solutions that we have discussed above which are ensuring data consistency:
- Repeatable Read isolation level
- Optimistic locking (Read Commited isolation level)
- Pessimistic locking (Read Commited isolation level)
To make it more realistic I am adding 10 000 dummy rows to the accounts table. Now lets take a look at threads config in JMeter:
We will be simulating 100 users with 50 seconds ramp-up period and whole experiment will take 150 seconds. It means that number of users will gradually rise during the first 50 seconds and then during 100 seconds all 100 users will be active.
Here are the results:
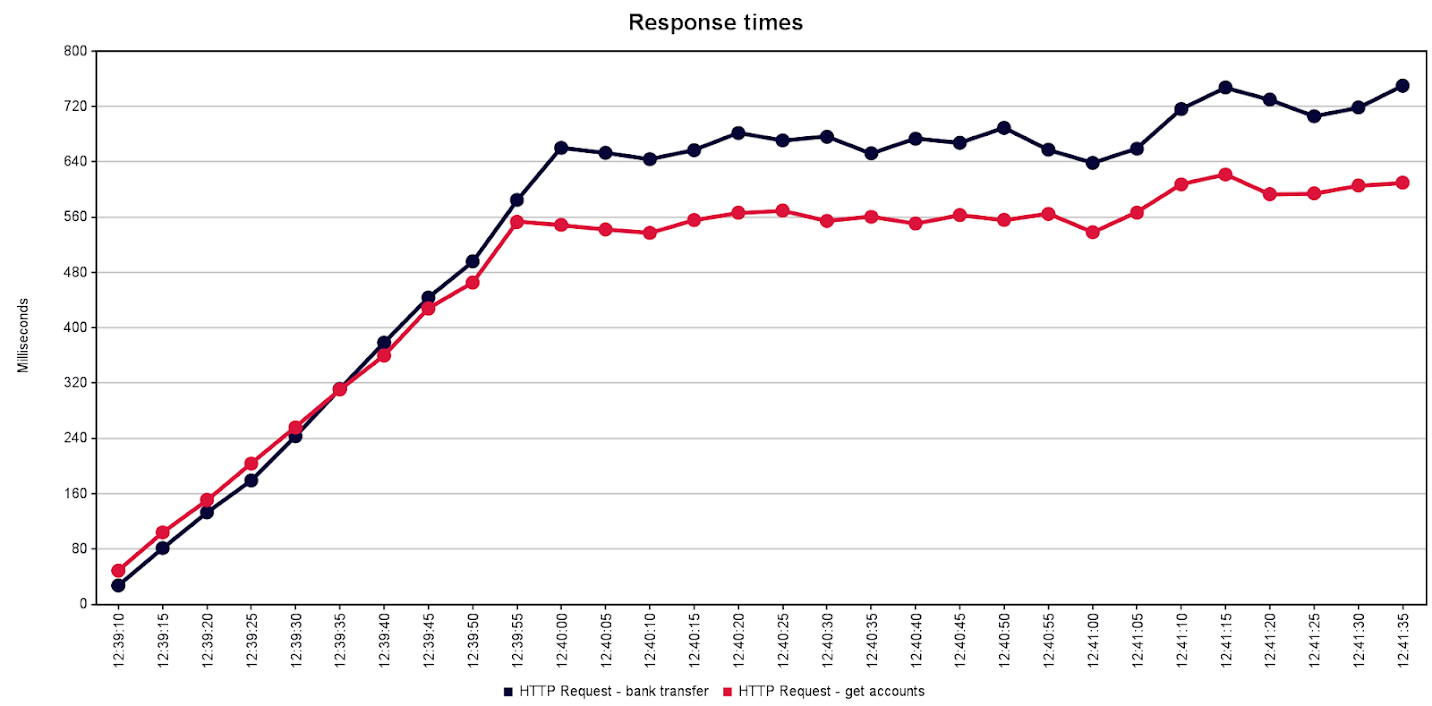
Repeatable Read
Optimistic locking
Pessimistic locking
Looking at the response time when all the users (100) were active we can see following results:
| Repeatable Read | Optimistic locking | Pessimistic locking | |
| Bank transfer [ms] | 640-760 | 560-720 | 700-950 |
| Accounts retrieval [ms] | 540-620 | 480-620 | 540-740 |
Thus we can conclude that the Optimistic Locking approach was the best from performance point of view. Repeatable read was pretty close having slightly worse results. For pessimistic locking we can notice longer response, especialy for bank transfer requests.
Summary
We have gone through a number of potential implementations of bank transfer in a web application:
- No explicit database transactions (each SQL statement has its own transaction) - rejected due to data consistency issues:
- Risk of inconsistent state when exception/error happens.
- Lost updates.
- Read Commited transaction - rejected due to data consistency issue:
- Lost updates.
- Repeatable Eead transaction - accepted since the data consistency is fulfilled. Not all of the requests are finished due to concurrent update exceptions.
- Optimistic Locking - accepted since the data consistency is fulfilled. This mechanism also results in not all the requests being finished successfully.
- Pessimistic Locking - accepted since the data consistency is fulfilled. All the requests are fulfilled but the performance is worse than for Optimistic Locking and Repeatable Read. When implementing this solution we also need to protect against deadlocks.

Komentarze
Prześlij komentarz